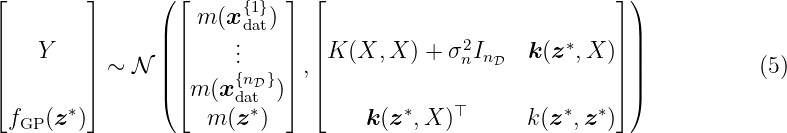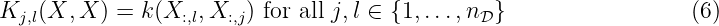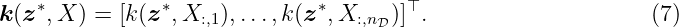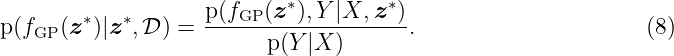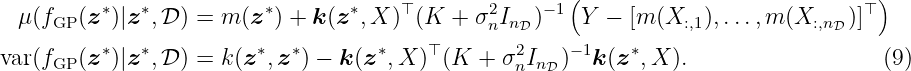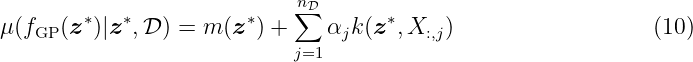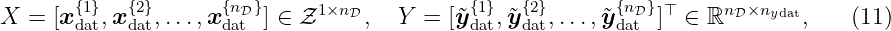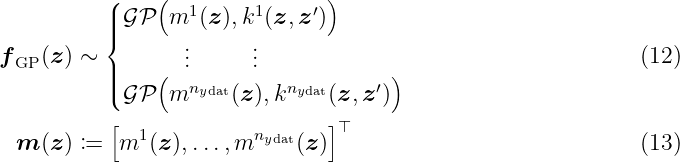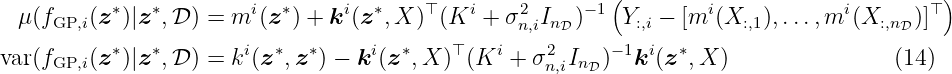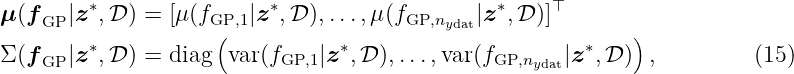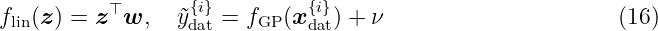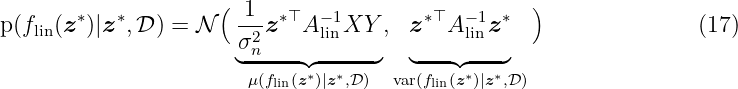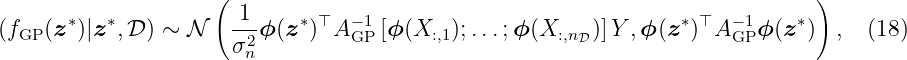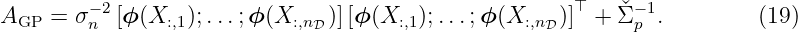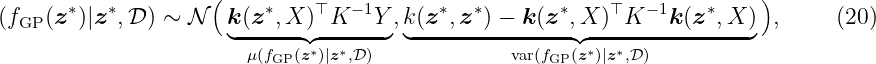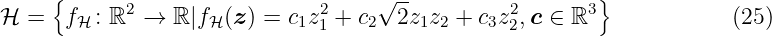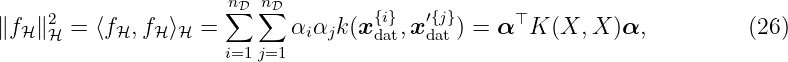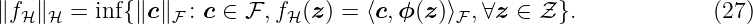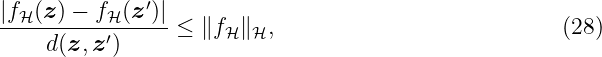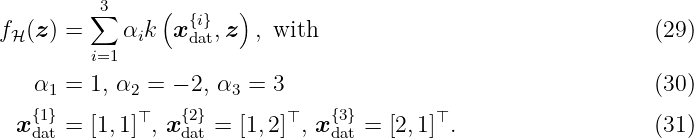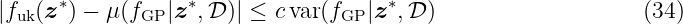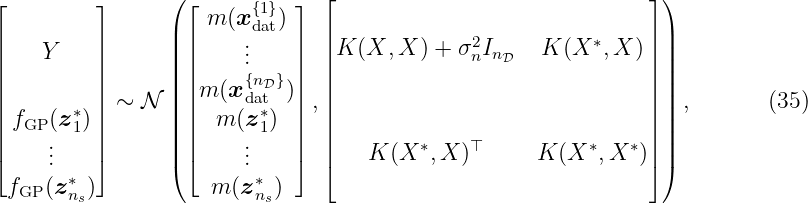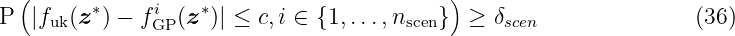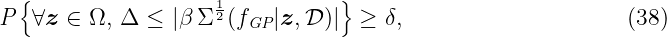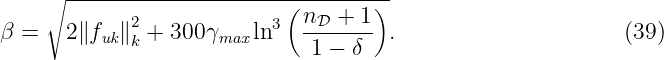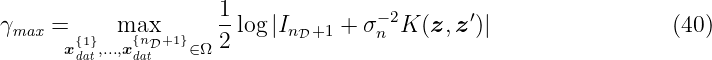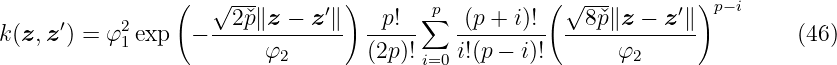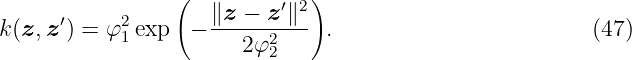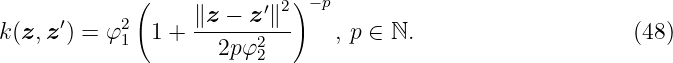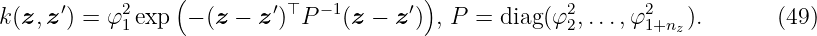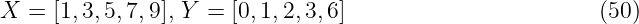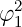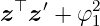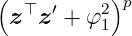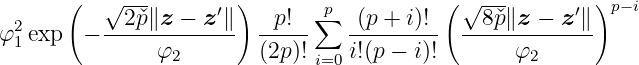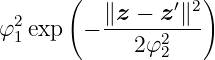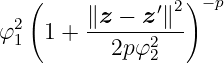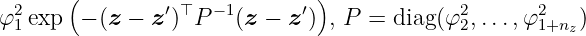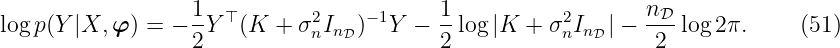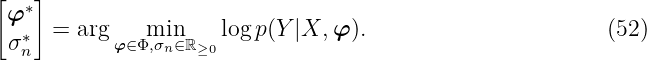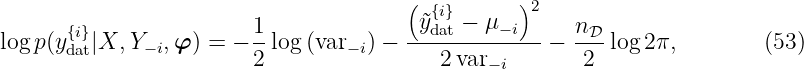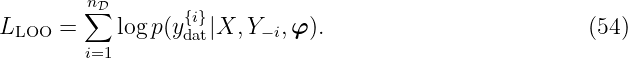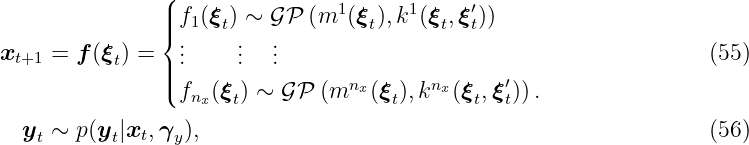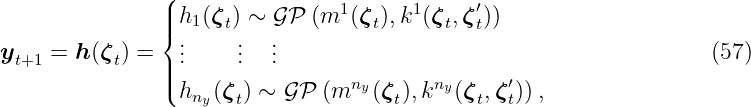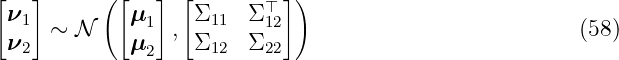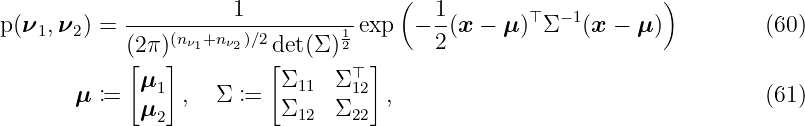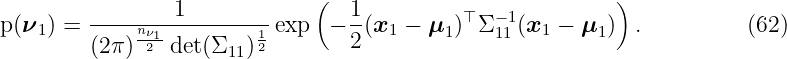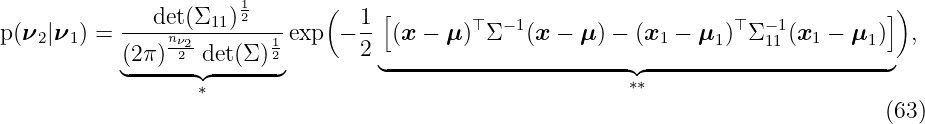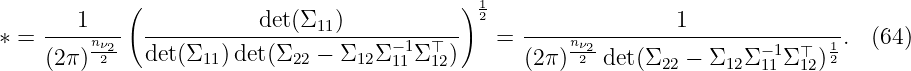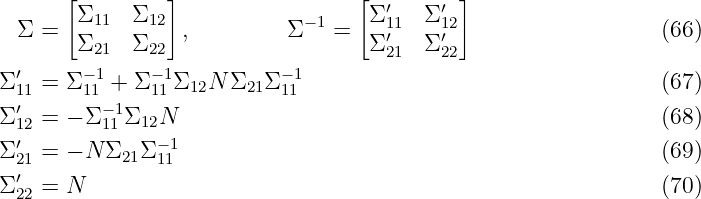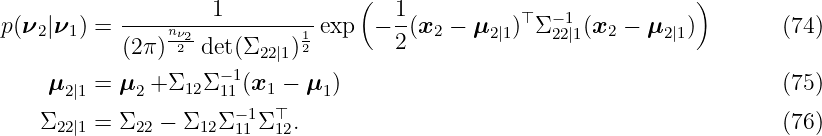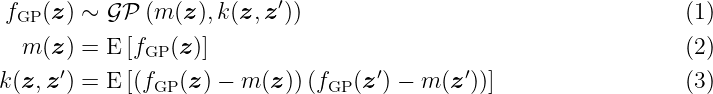
An Introduction to Gaussian
Process Models
by
Thomas Beckers, t.beckers@tum.de
Download as pdf
Within the past two decades, Gaussian process regression has been increasingly used for modeling dynamical systems due to some beneficial properties such as the bias variance trade-off and the strong connection to Bayesian mathematics. As data-driven method, a Gaussian process is a powerful tool for nonlinear function regression without the need of much prior knowledge. In contrast to most of the other techniques, Gaussian Process modeling provides not only a mean prediction but also a measure for the model fidelity. In this article, we give an introduction to Gaussian processes and its usage in regression tasks of dynamical systems.
A Gaussian process (GP) is a stochastic process that is in general a collection of random variables
indexed by time or space. Its special property is that any finite collection of these variables follows
a multivariate Gaussian distribution. Thus, the GP is a distribution over infinitely many variables
and, therefore, a distribution over functions with a continuous domain. Consequently, it describes a
probability distribution over an infinite dimensional vector space. For engineering applications, the
GP has gained increasing attention as supervised machine learning technique, where
it is used as prior probability distribution over functions in Bayesian inference. The
inference of continuous variables leads to Gaussian process regression (GPR) where the
prior GP model is updated with training data to obtain a posterior GP distribution.
Historically, GPR was used for the prediction of time series, at first presented by Wiener and
Kolmogorov in the 1940’s. Afterwards, it became increasingly popular in geostatistics in the
1970’s, where GPR is known as kriging. Recently, it came back in the area of machine
learning [Rad96; WR96], especially boosted by the rapidly increasing computational
power.
In this article, we present background information about GPs and GPR, mainly based on [Ras06],
focusing on the application in control. We start with an introduction of GPs, explain the role of
the underlying kernel function and show its relation to reproducing kernel Hilbert spaces.
Afterwards, the embedding in dynamical systems and the interpretation of the model uncertainty
as error bounds is presented. Several examples are included for an intuitive understanding in
addition to the formal notation.
Let (Ωss, Fσ, P) be a probability space with the sample space Ωss, the corresponding σ-algebra Fσ and the probability measure P. The index set is given by Z ⊆ ℝnz with positive integer n z. Then, a function fGP(z, ωss), which is a measurable function of ωss ∈ Ωss with index z ∈Z, is called a stochastic process. The function fGP(z, ωss) is a random variable on Ωss if z ∈ Z is specified. It is simplified written as fGP(z). A GP is a stochastic process which is fully described by a mean function m: Z → ℝ and covariance function k: Z ×Z → ℝ such that
with z, z′ ∈Z. The covariance function is a measure for the correlation of two states (z, z′) and is called kernel in combination with GPs. Even though no analytic description of the probability density function of the GP exists in general, the interesting property is that any finite collection of its random variables {fGP(z1), …, fGP(znGP)} follows a nGP-dimensional multivariate Gaussian distribution. As a GP defines a distribution over functions, each realization is also a function over the index set Z.
Example 1. A GP fGP(tc) ∼GP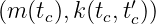 with time tc ∈ ℝ≥0, where
with time tc ∈ ℝ≥0, where
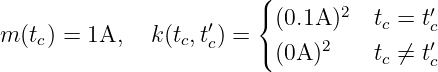
describes a time-dependent electric current signal with Gaussian white noise with a standard deviation of 0.1 A and a mean of 1 A.
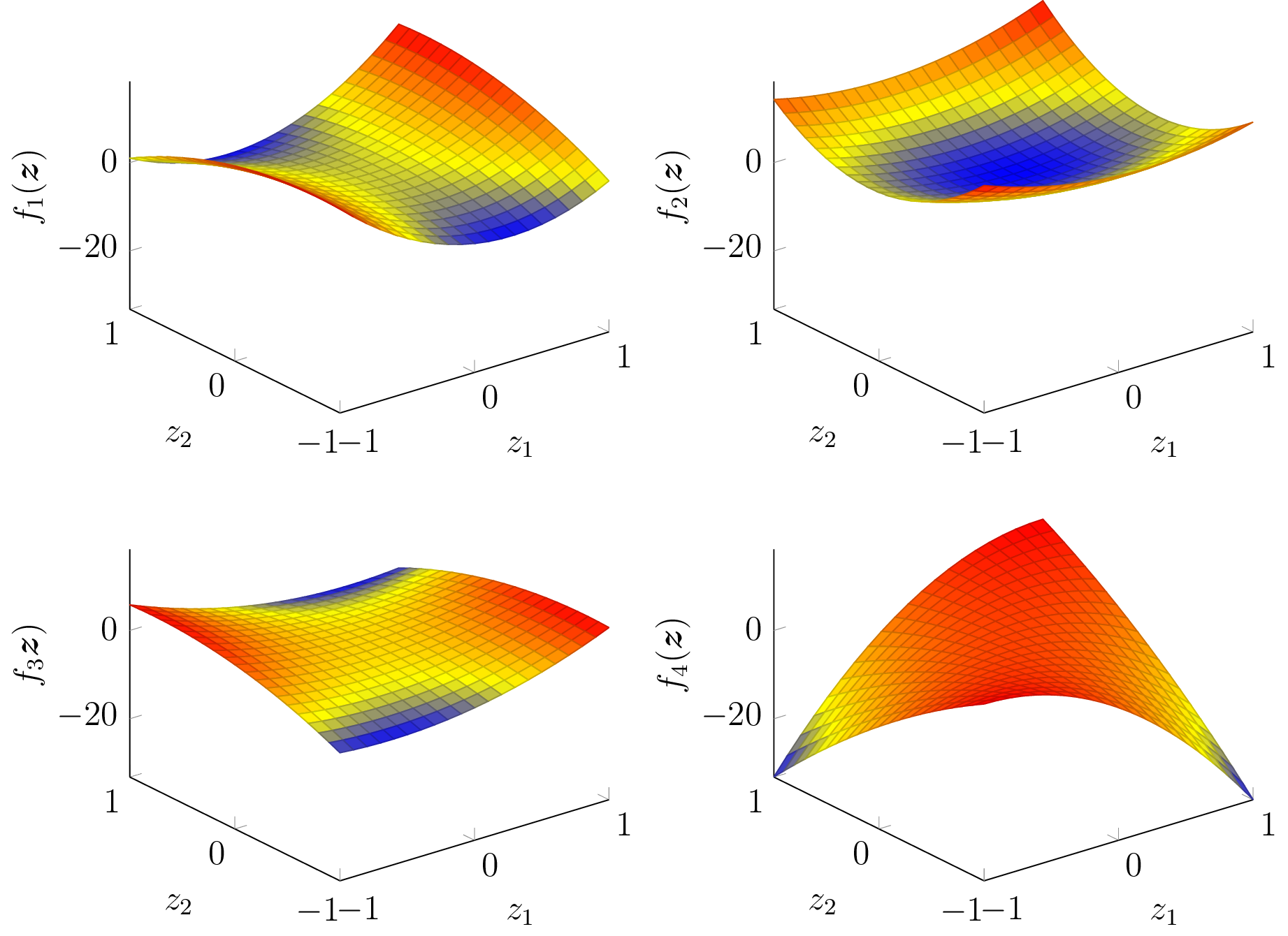
The GP can be utilized as prior probability distribution in Bayesian inference, which allows to perform function regression. Following the Bayesian methodology, new information is combined with existing information: using Bayes’ theorem, the prior is combined with new data to obtain a posterior distribution. The new information is expressed as training data set D = {X, Y }. It contains the input values X = [xdat{1}, xdat{2}, …, xdat{nD}] ∈ Z1×nD and output values Y = [ỹdat{1}, ỹdat{2}, …, ỹdat{nD}]⊤ ∈ ℝnD, where
for all i = 1, …, nD. The output data might be corrupted by Gaussian noise ν ∼N(0, σn2).
Remark 1. Note that we always use the standard notation X for the input training data and Y for the output training data throughout this report.
As any finite subset of a GP follows a multivariate Gaussian distribution, we can write the joint distribution
for any arbitrary test point z∗ ∈Z. The function m: Z → ℝ denotes the mean function. The matrix function K : Z1×nD ×Z1×nD → ℝnD×nD is called the covariance or Gram matrix with
where each element of the matrix represents the covariance between two elements of the training data X. The expression X:,l denotes the l-th column of X. For notational simplification, we shorten K(X, X) to K when necessary. The vector-valued kernel function k: Z×Z1×nD → ℝnD calculates the covariance between the test input z∗ and the input training data X, i.e.,
To obtain the posterior predictive distribution of fGP(z∗), we condition on the test point z∗ and the training data set D given by
Thus, the conditional posterior Gaussian distribution is defined by the mean and the variance
A detailed derivation of the posterior mean and variance based on the joint distribution (5) can
be found in Section 6. Analyzing (9) we can make the following observations:
i) The mean prediction can be written as
with α = (K + σn2I
nD)−1![( )
Y − [m (X:,1),...,m (X:,nD)]⊤](tutorial_material_html10x.png) ∈ ℝnD. That formulation highlights
the data-driven characteristic of the GPR as the posterior mean is a sum of kernel functions and
its number grows with the number nD of training data.
∈ ℝnD. That formulation highlights
the data-driven characteristic of the GPR as the posterior mean is a sum of kernel functions and
its number grows with the number nD of training data.
ii) The variance does not depend on the observed data, but only on the inputs, which is a
property of the Gaussian distribution. The variance is the difference between two terms:
The first term k(z∗, z∗) is simply the prior covariance from which a (positive) term is
subtracted, representing the information the observations contain about the function. The
uncertainty of the prediction, expressed in the variance, holds only for fGP(z∗) and
does not consider the noise in the training data. For this purpose, an additional noise
term σn2I
nD can be added to the variance in (9). Finally, (9) clearly shows the strong
dependence of the posterior mean and variance on the kernel k that we will discuss in depth
in Section 3.
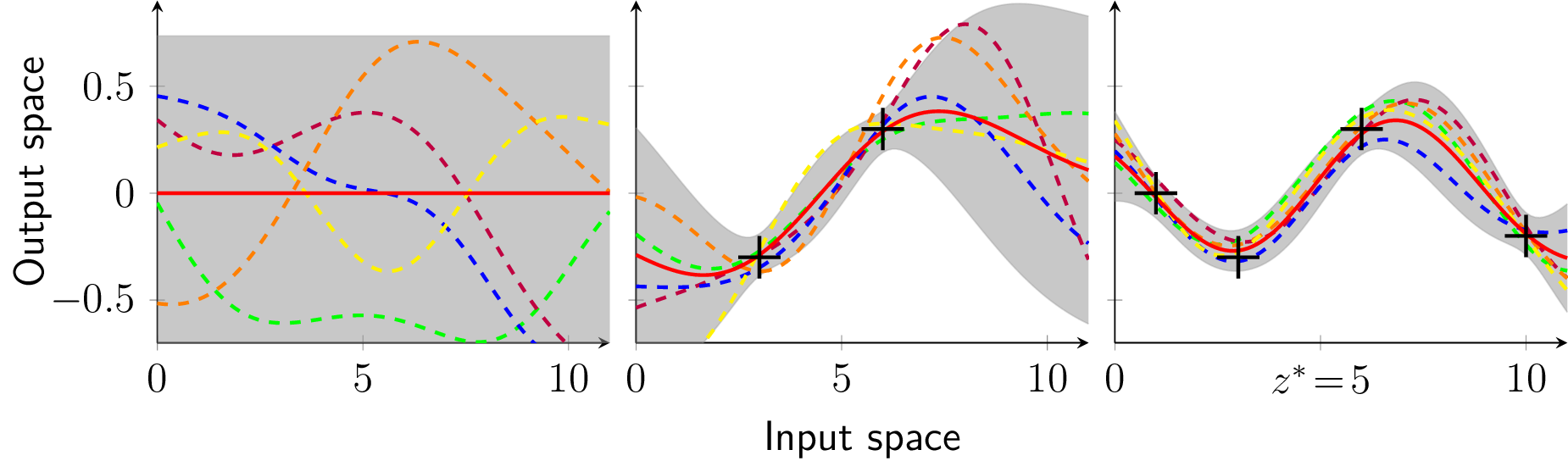
Example 2. We assume a GP with zero mean and a kernel function given by
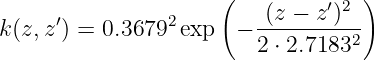
as prior distribution. The training data set D is assumed to be
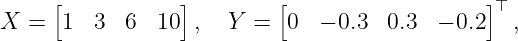
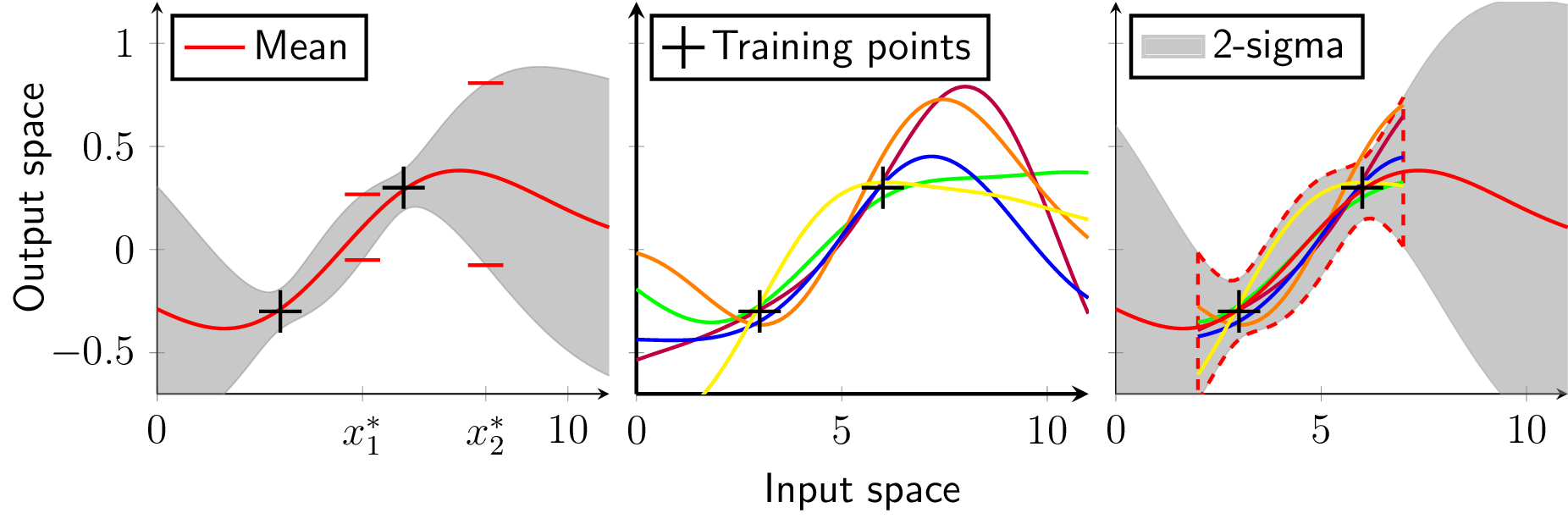
where the output is corrupted by Gaussian noise with σn = 0.0498 standard deviation and the test point is assumed to be z∗ = 5. According to (6) to (9) the Gram matrix K(X, X) is calculated as

and the kernel vector k(z∗, X) and k(z∗, z∗) are obtained to be
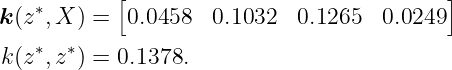
Finally, with (9), we compute the predicted mean and variance for fGP(z∗)
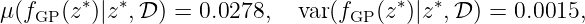
which is equivalent to a 2σ-standard deviation of 0.0775. Figure 1 shows the prior distribution (left), the posterior distribution with two training points (black crosses) in the middle, and the posterior distribution given the full training set D (right). The solid red line is the mean function and the gray shaded area indicates the 2σ-standard deviation. Five realizations (dashed lines) visualize the character of the distribution over functions.
So far, the GP regression allows functions with scalar outputs as in (9). For the extension to vector-valued outputs, multiple approaches exist: i) Extending the kernel to multivariate outputs [ÁRL12], ii) adding the output dimension as training data [Ber+17] or iii) using separated GPR for each output [Ras06]. While the first two approaches set a prior on the correlation between the output dimensions, the latter disregards a correlation without loss of generality. Following the approach in iii), the previous definition of the training set D is extended to a vector-valued output with
where nydat ∈ ℕ is the dimension of the output and the vector-valued GP is defined by
Following (5) to (9), we obtain for the predicted mean and variance
for each output dimension i ∈{1, …, nydat} with respect to the kernels k1, …, knydat. The variable σn,i denotes the standard deviation of the Gaussian noise that corrupts the i-th dimension of the output measurements. The nydat components of fGP|z∗, D are combined into a multi-variable Gaussian distribution with
where Σ(fGP|z∗, D) denotes the posterior variance matrix. This formulation allows to use a GP prior on vector-valued functions to perform predictions for test points z∗. This approach treats each output dimension separately which is mostly sufficient and easy-to-handle. An alternative approach is to include the dimension as additional input, e.g., as in [Ber+17], with the benefit of a single GP at the price of loss of interpretability. For highly correlated output data, a multi-output kernel might be beneficial, see [ÁRL12].
Remark 2. Without specific knowledge about a trend in the data, the prior mean functions m1, …, mnydat are often set to zero, see [Ras06]. Therefore, we set the mean functions to zero for the remainder of the report if not stated otherwise.
In Section 2.1, we target the GPR from a Bayesian perspective. However, for some applications of GPR a different point of view is beneficial; namely from the kernel perspective. In the following, we derive GPR from linear regression that is extended with a kernel transformation. In general, the prediction of parametric models is based on a parameter vector w which is typically learned using a set of training data points. In contrast, non-parametric models typically maintain at least a subset of the training data points in memory in order to make predictions for new data points. Many linear models can be transformed into a dual representation where the prediction is based on a linear combination of kernel functions. The idea is to transform the data points of a model to an often high-dimensional feature space where a linear regression can be applied to predict the model output, as depicted in Fig. 2. For a nonlinear feature map ϕ: Z →F, where F is a nϕ ∈ ℕ ∪{∞} dimensional Hilbert space, the kernel function is given by the inner product k(z, z′) = ⟨ϕ(z), ϕ(z′)⟩, ∀z, z′ ∈ Z.
Thus, the kernel implicitly encodes the way the data points are transformed into a higher dimensional space. The formulation as inner product in a feature space allows to extend many standard regression methods. Also the GPR can be derived using a standard linear regression model
where z ∈ Z is the input vector, w ∈ ℝnz the vector of weights with n z = dim(Z) and flin: Z → ℝ the unknown function. The observed value ỹdat{i} ∈ ℝ for the input xdat{i} ∈Z is corrupted by Gaussian noise ν ∼N(0, σ n2) for all i = 1, …, n D. The analysis of this model is analogous to the standard linear regression, i.e., we put a prior on the weights such that w ∼ N(0, Σp) with Σp ∈ ℝnz×nz. Based on n D collected training data points as defined in Section 2.1, that leads to the well known linear Bayesian regression
where Alin = σn−2XX⊤ + Σ p−1. Now, using the feature map ϕ(z) instead of z directly, leads to fGP(z) = ϕ(z)⊤w with w ∼N(0, Σ p), Σp ∈ ℝnϕ×nϕ. As long as the projections are fixed functions, i.e., independent of the parameters w, the model is still linear in the parameters and, thus, analytically tractable. In particular, the Bayesian regression (17) with the mapping ϕ(z) can be written as
with the matrix AGP ∈ ℝnϕ×nϕ given by
This equation can be simplified and rewritten to
with k(z, z′) = ϕ(z)⊤Σ pϕ(z′) that equals (9). The fact that in (20) the feature map ϕ(z) is not needed is known as the kernel trick. This trick is also used in other kernel-based models, e.g., support vector machines (SVM), see [SC08] for more details.
Even though a kernel neither uniquely defines the feature map nor the feature space, one can always construct a canonical feature space, namely the reproducing kernel Hilbert space (RKHS) given a certain kernel. After the introduction of the theory, illustrative examples for an intuitive understanding are presented. We will now formally present this construction procedure, starting with the concept of Hilbert spaces, following [BLG16]: A Hilbert space F represents all possible realizations of some class of functions, for example all functions of continuity degree i, denoted by Ci. Moreover, a Hilbert space is a vector space such that any function f F ∈F must have a non-negative norm, ∥fF∥F > 0 for fF≠0. All functions fF must additionally be equipped with an inner-product in F. Simply speaking, a Hilbert space is an infinite dimensional vector space, where many operations behave like in the finite case. The properties of Hilbert spaces have been explored in great detail in literature, e.g., in [DM+05]. An extremely useful property of Hilbert spaces is that they are equivalent to an associated kernel function [Aro50]. This equivalence allows to simply define a kernel, instead of fully defining the associated vector space. Formally speaking, if a Hilbert space H is a RKHS, it will have a unique positive definite kernel k: Z ×Z → ℝ, which spans the space H.
Theorem 1 (Moore-Aronszajn [Aro50]). Every positive definite kernel k is associated with a unique RKHS H.
Theorem 2 ([Aro50]). Let F be a Hilbert space, Z a non-empty set and ϕ: Z →F. Then, the inner product ⟨ϕ(z), ϕ(z′)⟩ F : = k(z, z′) is positive definite.
Importantly, any function fH in H can be represented as a weighted linear sum of this kernel evaluated over the space H, as
with αi ∈ ℝ for all i = {1, …, nϕ}, where nϕ ∈ ℕ ∪{∞} is the dimension of the feature space F. Thus, the RKHS is equipped with the inner-product
with fH′(⋅) = ∑
j=1nϕα
j′k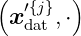 ∈H, αj′ ∈ ℝ. Now, the reproducing character manifests
as
∈H, αj′ ∈ ℝ. Now, the reproducing character manifests
as
According to [SHS06], the RKHS is then defined as
where ϕ(z) is the feature map constructing the kernel through k(z, z′) = ⟨ϕ(z), ϕ(z′)⟩ F.
Example 3. We want to find the RKHS for the polynomial kernel with degree 2 that is given by
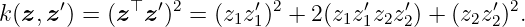
for any z, z′ ∈ ℝ2. First, we have to find a feature map ϕ such that the kernel corresponds to the inner product k(z, y) = ⟨ϕ(z), ϕ(y)⟩. A possible candidate for the feature map is
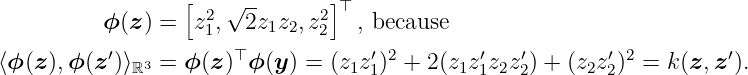
We know that the RKHS contains all linear combinations of the form
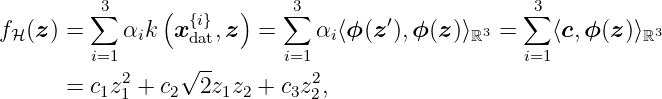
with α, c, xdat{i} ∈ ℝ3. Therefore, a possible candidate for the RKHS H is given by
Next, it must be checked if the proposed Hilbert space is the related RKHS to the polynomial kernel with degree 2. This is achieved in two steps: i) Checking if the space is a Hilbert space and ii) confirming the reproducing property. First, we can easily proof that this is a Hilbert space rewriting fH(z) = z⊤Sz with symmetric matrix S ∈ ℝ2×2 and using the fact that H is euclidean and isomorphic to S. Second, the condition for an RKHS must be fulfilled, i.e., the reproducing property fH(z) = ⟨fH(⋅), k(⋅, z)⟩H. Since we can write
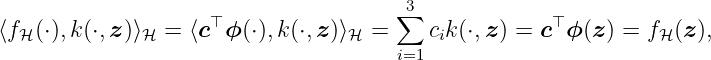
property (23) is fulfilled and, thus, H is the RKHS for the polynomial kernel with degree 2. Note that, even though the mapping ϕ is not unique for the kernel k, the relation of k and the RKHS H is unique.
Given a function fH ∈ H defined by nD observations, its RKHS norm is defined as
with α ∈ ℝnD and K(X, X) given by (6). We can also use the feature map such that
As there is a unique relation between the RKHS H and the kernel k, the norm ∥fH∥H can equivalently be written as ∥fH∥k. The norm of a function in the RKHS indicates how fast the function varies over Z with respect to the geometry defined by the kernel. Formally, it can be written as
with the distance d(z, z′)2 = k(z, z) − 2k(z, z′) + k(z′, z′). A function with finite RKHS norm is also element of the RKHS. A more detailed discussion about RKHS and norms is given in [Wah90].
Example 4. We want to find the RKHS norm of a function fH that is an element of the RKHS of the polynomial kernel with degree 2 that is given by
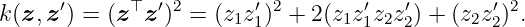
Let the function be
Hence, function (29) with (30) and (31) corresponds to
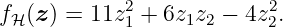
Now, we have two possibilities how to calculate the RKHS norm. First, the RKHS-norm of fH is calculated using (26) by
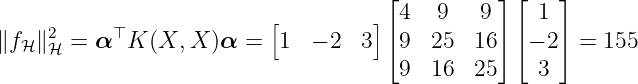
with X = [xdat{1}, xdat{2}, xdat{3}]. Alternatively, we can use (27) that results in ∥f H∥H = ∥c∥, where c is defined by (25). Thus, the norm is computed as
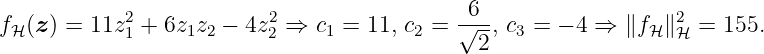
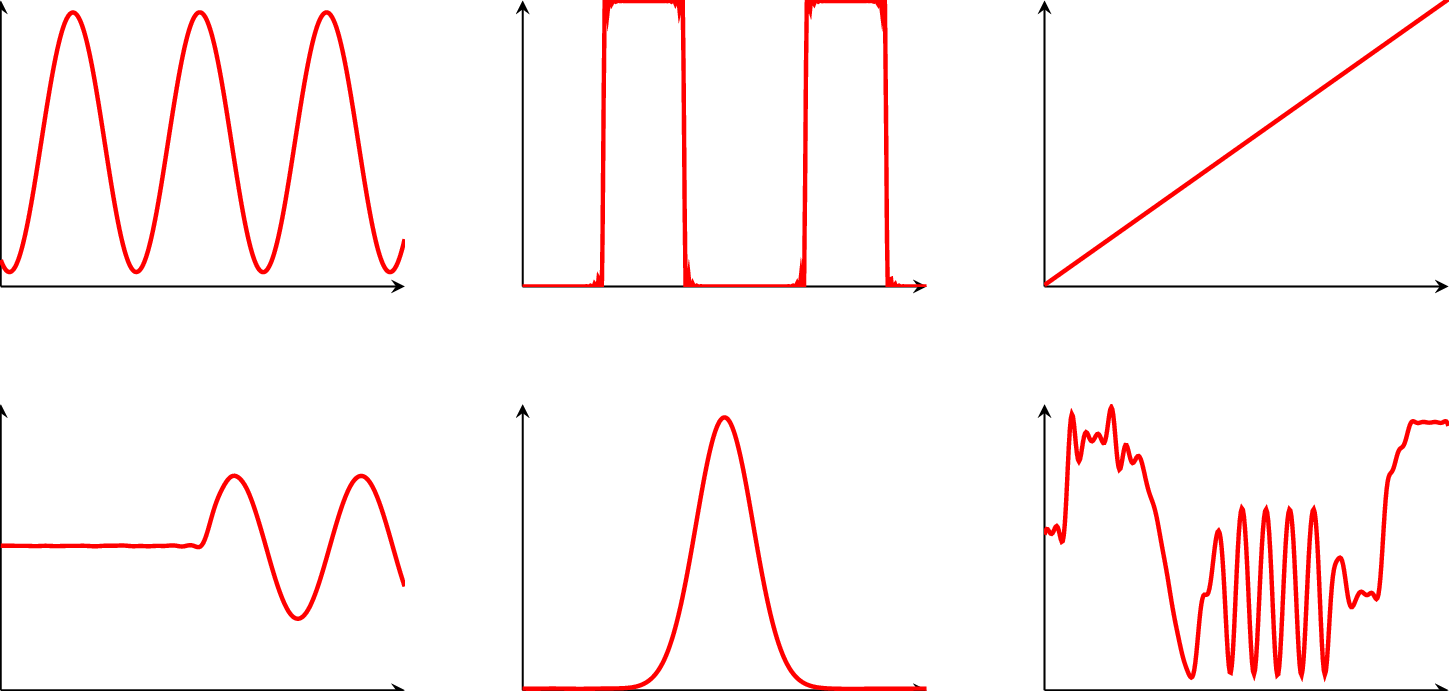
Example 5. In this example, we visualize the meaning of the RKHS norm. Figure 3 shows different quadratic functions with the same RKHS norm (top left and top right), a smaller RKHS norm (bottom left) and a larger RKHS norm (bottom right). An identical norm indicates a similar variation of the functions, whereas a higher norm leads to a more varying function.
In summary, we investigate the unique relation between the kernel and its RKHS. The reproducing property allows us to write the inner-product as a tractable function which implicitly defines a higher (or even infinite) feature dimensional space. The RKHS-norm of a function is a Lipschitz-like indicator based on the metric defined by the kernel. This view of the RKHS is related to the kernel trick in machine learning. In the next section, the RKHS-norm is exploited to determine the error between the prediction of GPR and the actual data-generating function.
One of the most interesting properties of GPR is the uncertainty description encoded in the predicted variance. This uncertainty is beneficial to quantify the error between the actual underlying data generating process and the GPR. In this section, we assume that there is an unknown function fuk: ℝnz → ℝ that generates the training data. In detail, the data set D = {X, Y } consists of
where the data is generated by
for all i = {1, …, nD}. Without any assumptions on fuk it is obviously not possible to quantify the model error. Loosely speaking, the prior distribution of the GPR with kernel k must be suitable to learn the unknown function. More technically, fuk must be an element of the RKHS spanned by the kernel as described in (24). This leads to the following assumption.
Assumption 1. The function fuk has a finite RKHS norm with respect to the kernel k, i.e., ∥fuk∥H < ∞, where H is the RKHS spanned by k.
This sounds paradoxical as fuk is assumed to be unknown. However, there exist kernels that can
approximate any continuous function arbitrarily exact. Thus, for any continuous function, an
arbitrarily close function is element of the RKHS of an universal kernel. For more details, we refer
to Section 2.4. More infomation about the model error of misspecified Gaussian Process model
can be found in [BUH18]
We classify the error quantification in three different approaches: i) the robust approach,
ii) the scenario approach, and iii) the information-theoretical approach. The different
techniques are presented in the following and visualized in Fig. 4. For the remainder of this
section, we assume that a GPR is trained with the data set (32) and Assumption 1
holds.
The robust approach exploits the fact that the prediction of the GPR is Gaussian distributed. Thus, for any z∗ ∈ ℝnz, the model error is bounded by
with high probability where c ∈ ℝ>0 adjusts the probability. However, for multiple test points z1∗, z 2∗, … ∈ ℝnz, this approach neglects any correlation between fGP(z 1∗), fGP(z 2∗), …. Figure 4 shows how for a given z1∗ and z 2∗, the variance is exploited as upper bound. Thus, any prediction is handled independently, which leads to a very conservative bound, see [UBH18].
Instead of using the mean and the variance as in the robust approach, the scenario approach deals with the samples of the GPR directly. In contrast to the other methods, there is no direct model error quantification but rather a sample based quantification. The idea is to draw a large number nscen ∈ ℕ of sample functions fGP1, fGP2, …, fGPnscen over n s ∈ ℕ sampling points. The sampling is performed by drawing multiple instances from fGP given by the multivariate Gaussian distribution
where X∗ = [z
1∗, 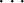 , z
ns∗] contains the sampling points. Each sample can then be used in the
application instead of the unknown function. For a large number of samples it is assumed that the
unknown function is close to one of these samples. However, the crux of this approach is to
determine, for a given model error c ∈ ℝ>0, the required number of samples nscen and
probability δscen > 0 such that
, z
ns∗] contains the sampling points. Each sample can then be used in the
application instead of the unknown function. For a large number of samples it is assumed that the
unknown function is close to one of these samples. However, the crux of this approach is to
determine, for a given model error c ∈ ℝ>0, the required number of samples nscen and
probability δscen > 0 such that
for all z∗ ∈ Z. In Fig. 4, five different samples of a GP model are drawn as example.
Alternatively, the work in [Sri+12] derives an upper bound for samples of the GPR on a compact set with a specific probability. In contrast to the robust approach, the correlation between the function values are considered. We restate here the theorem of [Sri+12].
Theorem 3 ([Sri+12]). Given Assumption 1, the model error Δ ∈ ℝ
is bounded for all z on a compact set Ω ⊂ ℝnz with a probability of at least δ ∈ (0, 1) by
where β ∈ ℝ is defined as
The variable γmax ∈ ℝ is the maximum of the information gain
with Gram matrix K(z, z′) and the input elements z, z′ ∈{xdat{1}, …, xdat{nD+1}}.
To compute this bound, the RKHS norm of fuk must be known. That is in application usually not the case. However, often the norm can be upper bounded and thus, the bound in Theorem 3 can be upper bounded. For this purpose, the relation of the RKHS norm to the Lipschitz constant given by (28) is beneficial as the Lipschitz constant is more likely to be known. In general, the computation of the information gain is a non-convex optimization problem. However, the information capacity γmax has a sub-linear dependency on the number of training points for many commonly used kernel functions [Sri+12]. Therefore, even though β is increasing with the number of training data, it is possible to learn the true function fuk arbitrarily exactly [Ber+16]. In contrast to the other approaches, Theorem 3 allows to bound the error for any test point in a compact set. In [BKH19], we exploit this approach in GP model based control tasks. The right illustration of Fig. 4 visualizes the information-theoretical bound.
Equation (9) clearly shows the immense impact of the kernel on the posterior mean and variance. However, this is not surprising as the kernel is an essential part of the prior model. For practical applications that leads to the question how to choose the kernel. Additionally, most kernels depend on a set of hyperparameters that must be defined. Thus in order to turn GPR into a powerful practical tool it is essential to develop methods that address the model selection problem. We see the model selection as the determination of the kernel and its hyperparameters. We only focus on kernels that are defined on Z ⊆ ℝnz. In the next two subsections, we present different kernels and explain the role of the hyperparameters and their selection, mainly based on [Ras06].
Remark 3. The selection of the kernel functions seems to be similar to the model selection for parametric models. However, there are two major differences: i) the selection is fully covered by the Bayesian methodology and ii) many kernels allow to model a wide range of different functions whereas parametric models a typically limited to very specific types of functions.
The value of the kernel function k(z, z′) is an indicator of the interaction of two states (z, z′). Thus, an essential part of GPR is the selection of the kernel function and the estimation of its free parameters φ1, φ2, …, φnφ, called hyperparameters. The number nφ of hyperparameters depends on the kernel function. The choice of the kernel function and the determination of the corresponding hyperparameters can be seen as degrees of freedom of the regression. First of all, we start with the general properties of a function to be qualified as a kernel for GPR. A necessary and sufficient condition for the function k: Z ×Z → ℝ to be a valid kernel is that the Gram matrix, see (6), is positive semidefinite for all possible input values [SC04].
Remark 4. As shown in Section 2.4, the kernel function must be positive definite to span an unique RKHS. That seems to be contradictory to the required positive semi-definiteness of the Gram matrix. The solution is the definition of positive definite kernels as it is equivalent to a positive semi-definite Gram matrix. In detail, a symmetric function k: Z×Z → ℝ is a positive definite kernel on Z if
holds for any nD ∈ ℕ, xdat{1}, …, xdat{nD} ∈Z and c 1, …, cn ∈ ℝ. Thus, there exists a positive semi-definite matrix AG ∈ ℝnD×nD such that
holds for any nD ∈ ℕ and z ∈Z.
The set of functions k which fulfill this condition is denoted with K. Kernel functions can be separated into two classes, the stationary and non-stationary kernels. A stationary kernel is a function of the distance z −z′. Thus, it is invariant to translations in the input space. In contrast, non-stationary kernels depend directly on z,z′ and are often functions of a dot product z⊤z. In the following, we list some common kernel functions with their basic properties. Even though the number of presented kernels is limited, new kernels can be constructed easily as K is closed under specific operations such as addition and scalar multiplication. At the end, we summarize the equation of each kernel in Table 1 and provide a comparative example.
The equation for the constant kernel is given by
This kernel is mostly used in addition to other kernel functions. It depends one a single hyperparameter φ1 ∈ ℝ≥0.
The equation for the linear kernel is given by
The linear kernel is a dot-product kernel and thus, non-stationary. The kernel can be obtained from Bayesian linear regression as shown in Section 2.3. The linear kernel is often used in combination with the constant kernel to include a bias.
The equation for the polynomial kernel is given by
The polynomial kernel has an additional parameter p ∈ ℕ, that determines the degree of the polynomial. Since a dot product is contained, the kernel is also non-stationary. The prior variance grows rapidly for ∥z∥ > 1 such that the usage for some regression problems is limited. It depends on a single hyperparameter φ1 ∈ ℝ≥0.
The equation for the Matérn kernel is given by
with p = p + 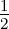 , p ∈ ℕ. The Matérn kernel is a very powerful kernel and presented here with
the most common parameterization for p. Functions drawn from a GP model with Matérn
kernel are p-times differentiable. The more general equation of this stationary kernel
can be found in [Bis06]. This kernel is an universal kernel which is explained in the
following.
, p ∈ ℕ. The Matérn kernel is a very powerful kernel and presented here with
the most common parameterization for p. Functions drawn from a GP model with Matérn
kernel are p-times differentiable. The more general equation of this stationary kernel
can be found in [Bis06]. This kernel is an universal kernel which is explained in the
following.
Lemma 1 ([SC08, Lemma 4.55]). Consider the RKHS H(Zc) of an universal kernel on any prescribed compact subset Zc ∈Z. Given any positive number 𝜀 and any function fC ∈ C1(Z C), there is a function fH ∈H(Zc) such that ∥fC − fH∥Zc ≤ 𝜀.
Intuitively speaking, a GPR with an universal kernel can approximate any continuous function arbitrarily exact on a compact set. For p →∞, it results in the squared exponential kernel. The two hyperparameters are φ1 ∈ ℝ≥0 and φ2 ∈ ℝ>0.
The equation for the squared exponential kernel is given by
Probably the most widely used kernel function for GPR is the squared exponential kernel, see [Ras06]. The hyperparameter φ1 describes the signal variance which determines the average distance of the data-generating function from its mean. The lengthscale φ2 defines how far it is needed to move along a particular axis in input space for the function values to become uncorrelated. Formally, the lengthscale determines the number of expected upcrossings of the level zero in a unit interval by a zero-mean GP. The squared exponential kernel is infinitely differentiable, which means that the GPR exhibits a smooth behavior. As limit of the Matérn kernel, it is also an universal kernel, see [MXZ06].
Example 6. Figure 5 shows the power for regression of universal kernel functions. In this example, a GPR with squared exponential kernel is used for different training data sets. The hyperparameter are optimized individually for each training data set by means of the likelihood, see Section 3.2. Note that all presented regressions are based on the same GP model, i.e. the same kernel function, but with different data sets. That highlights again the superior flexibility of GPR.
The equation for the rational quadratic kernel is given by
This kernel is equivalent to summing over infinitely many squared exponential kernels with different lengthscales. Hence, GP priors with this kernel are expected to see functions which vary smoothly across many lengthscales. The parameter p determines the relative weighting of large-scale and small-scale variations. For p →∞, the rational quadratic kernel is identical to the squared exponential kernel.
The equation for the squared exponential ARD kernel is given by
The automatic relevance determination (ARD) extension to the squared exponential kernel allows for independent lenghtscales φ2, …, φ1+nz ∈ ℝ>0 for each dimension of z, z′ ∈ ℝnz. The individual lenghtscales are typically larger for dimensions which are irrelevant as the covariance will become almost independent of that input. A more detailed discussion about the advantages of different kernels can be found, for instance, in [Mac97] and [Bis06].
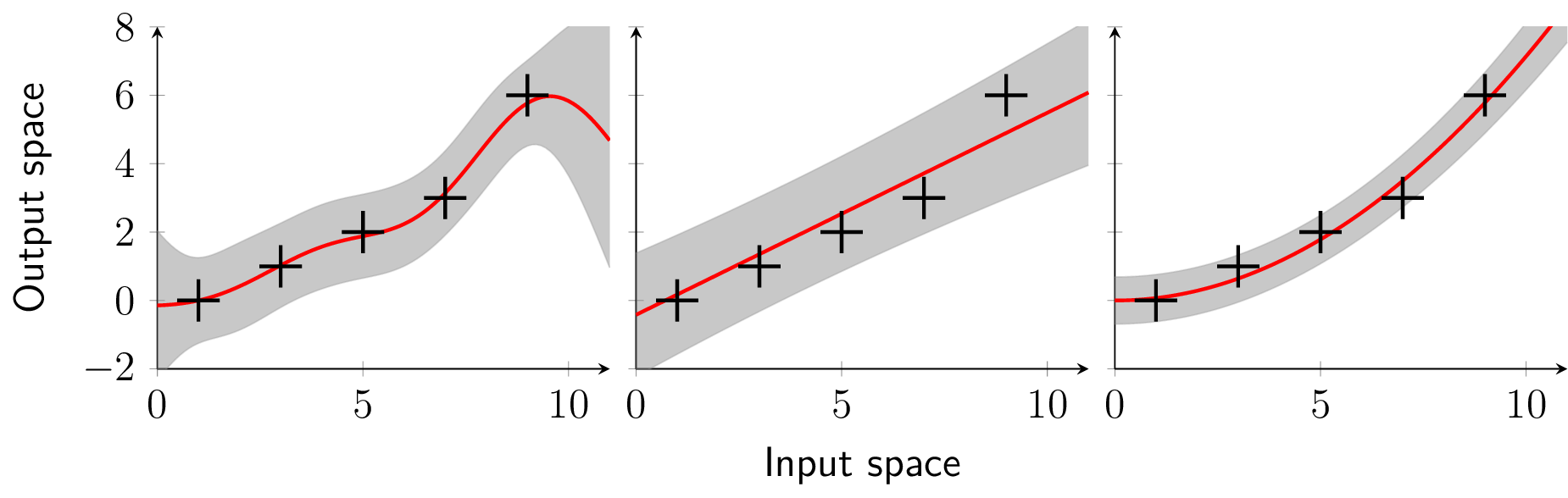
Example 7. In this example, we use three GPRs with the same set of training data
but with different kernels, namely the squared exponential (47), the linear (44), and the polynomial (45) kernel. Figure 6 shows the different shapes of the regressions with the posterior mean (red), the posterior variance (gray shaded) and the training points (black). Even for this simple data set, the flexibility of the squared exponential kernel is already visible.
In addition to the selection of a kernel function, values for any hyperparameter must be determined to perform the regression. The number of hyperparameters depends on the kernel function used. We concatenate all hyperparameters in a vector φ with size nφ ∈ ℕ, where φ ∈ Φ ⊆ ℝnφ. The hyperparameter set Φ is introduced to cover the different spaces of the individual hyperparameters as defined in the following.
Definition 1. The set Φ is called a hyperparameter set for a kernel function k if and only if the set Φ is a domain for the hyperparameters φ of k.
Often, the signal noise σn2, see (5), is also treated as hyperparameter. For a better understanding, we keep the signal noise separated from the hyperparameters. There exist several techniques that allow computing the hyperparameters and the signal noise with respect to one optimality criterion. From a Bayesian perspective, we want to find the vector of hyperparameters φ which are most likely for the output data Y given the inputs X and a GP model. For this purpose, one approach is to optimize the log marginal likelihood function of the GP. Another idea is to split the training set into two disjoint sets, one which is actually used for training, and the other, the validation set, which is used to monitor performance. This approach is known as cross-validation. In the following, these two techniques for the selection of hyperparameters are presented.
A very common method for the optimization of the hyperparameters is by means of the negative log marginal likelihood function, often simply named as (neg. log) likelihood function. It is marginal since it is obtained through marginalization over the function fGP. The marginal likelihood is the likelihood that the output data Y ∈ ℝnD fits to the input data X with the hyperparameters φ. It is given by
A detailed derivation can be found in [Ras06]. The three terms of the marginal likelihood in (51) have the following roles:
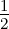 Y ⊤(K + σ
n2I
nD)−1Y is the only term that depends on the output data Y and
represents the data-fit.
Y ⊤(K + σ
n2I
nD)−1Y is the only term that depends on the output data Y and
represents the data-fit.
 log |K +σn2I
nD| penalizes the complexity depending on the kernel function and the
input data X.
log |K +σn2I
nD| penalizes the complexity depending on the kernel function and the
input data X.
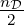 log 2π is a normalization constant.
log 2π is a normalization constant.Remark 5. For the sake of notational simplicity, we suppress the dependency on the hyperparameters of the kernel function k whenever possible.
The optimal hyperparameters φ∗ ∈ Φ and signal noise σ n∗ in the sense of the likelihood are obtained as the minimum of the negative log marginal likelihood function
Since an analytic solution of the derivation of (51) is impossible, a gradient based optimization algorithm is typically used to minimize the function. However, the negative log likelihood is non-convex in general such that there is no guarantee to find the optimum φ∗, σ n∗. In fact, every local minimum corresponds to a particular interpretation of the data. In the following example, we visualize how the hyperparameters affect the regression.
Example 8. A GPR with the squared exponential kernel is trained on eight data points. The signal variance is fixed to φ1 = 2.13. First, we visualize the influence of the lengthscale. For this purpose, the signal noise is fixed to σn = 0.21. Figure 7 shows the posterior mean of the regression and the neg. log likelihood function. On the left side are three posterior means for different lengthscales. A short lengthscale results in overfitting whereas a large lengthscale smooths out the training data (black crosses). The dotted red function represents the mean with optimized lengthscale by a descent gradient algorithm with respect to (52). The right plot shows the neg. log likelihood over the signal variance φ1 and lengthscale φ2. The minimum is here at φ∗ = [2.13, 1.58]⊤.
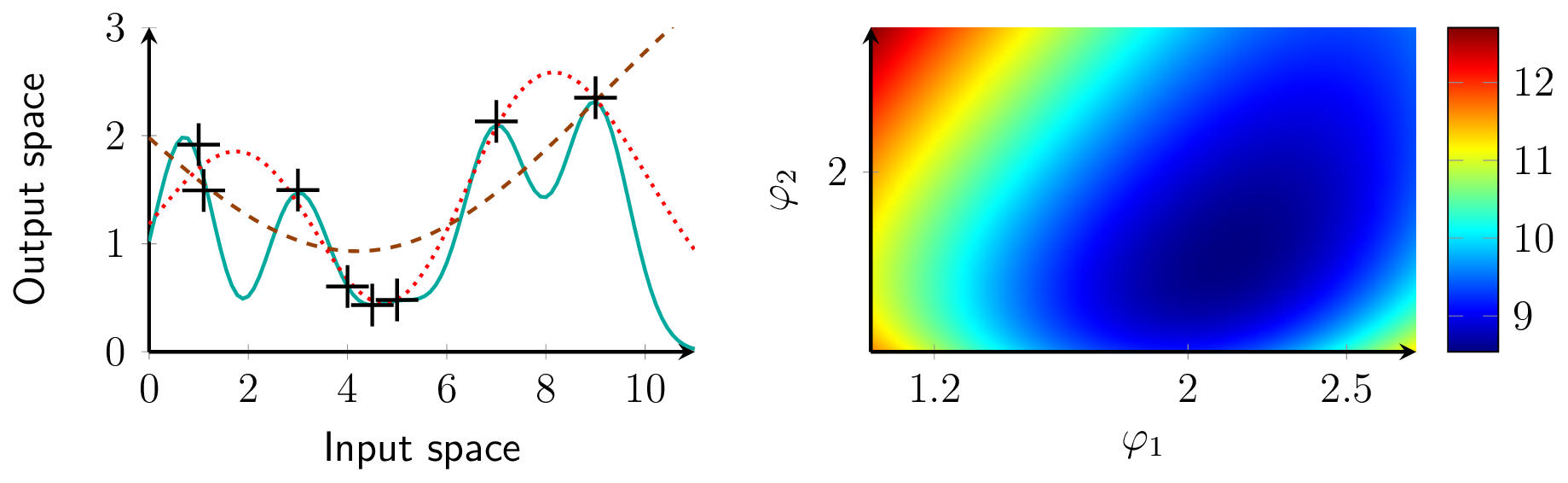
Next, the meaning of different interpretations of the data is visualized by varying the signal noise σn and the lengthscale φ2. The right plot of Fig. 8 shows two minima of the negative log likelihood function. The lower left minimum at log(σn) = 0.73 and log(φ2) = −1.51 interprets the data as slightly noisy which leads to the dotted red posterior mean in the left plot. In contrast, the upper right minimum at log(σn) = 5 and log(φ2) = −0.24 interprets the data as very noisy without a trend, which manifests as the cyan posterior mean in the left plot. Depending on the initial value, a gradient based optimizer would terminate in one of these minima.
This approach works with a separation of the data set D in two classes: one for training and one for validation. Cross-validation is almost always used in the kcv-fold cross-validation setting: the kcv-fold cross-validation data is split into kcv disjoint, equally sized subsets; validation is done on a single subset and training is done using the union of the remaining kcv − 1 subsets, the entire procedure is repeated kcv times, each time with a different subset for validation. Here, without loss of generality, we present the leave-one-out cross-validation, which means kcv = nD. The predictive log probability when leaving out a training point {xdat{i}, ỹdat{i}} is given by
where μ−i = μ(fGP(xdat{i})|xdat{i}, X :,−i, Y −i) and var −i = var(fGP(xdat{i})|xdat{i}, X :,−i, Y −i). The −i index indicates X and Y without the element xdat{i} and ỹdat{i}, respectively. Thus, (53) is the probability for the output ydat{i} at xdat{i} but without the training point {xdat{i}, ỹ{i}}. Accordingly, the leave-one-out log predictive probability LLOO ∈ ℝ is
In comparison to the log likelihood approach (52), the cross-validation is in general more computationally expensive but might find a better representation of the data set, see [GE79] for discussion and related approaches.
So far, we consider GPR in non-dynamical settings where only an input-to-output mapping is considered. However, Gaussian process dynamical models (GPDMs) have recently become a versatile tool in system identification because of their beneficial properties such as the bias variance trade-off and the strong connection to Bayesian mathematics, see [FCR14]. In many works, where GPs are applied to dynamical model, only the mean function of the process is employed, e.g., in [WHB05] and [Cho+13]. This is mainly because GP models are often used to replace deterministic parametric models. However, GPDMs contain a much richer description of the underlying dynamics, but also the uncertainty about the model itself when the full probabilistic representation is considered. Therefore, one main aspect of GPDMs is to distinguish between recurrent structures and non-recurrent structures. A model is called recurrent if parts of the regression vector depend on the outputs of the model. Even though recurrent models become more complex in terms of their behavior, they allow to model sequences of data, see [Sjö+95]. If all states are fed back from the model itself, we get a simulation model, which is a special case of the recurrent structure. The advantage of such a model is its property to be independent from the real system. Thus, it is suitable for simulations, as it allows multi-step ahead predictions. In this report, we focus on two often-used recurrent structures: the Gaussian process state space model (GP-SSM) and the Gaussian process nonlinear error output (GP-NOE) model.
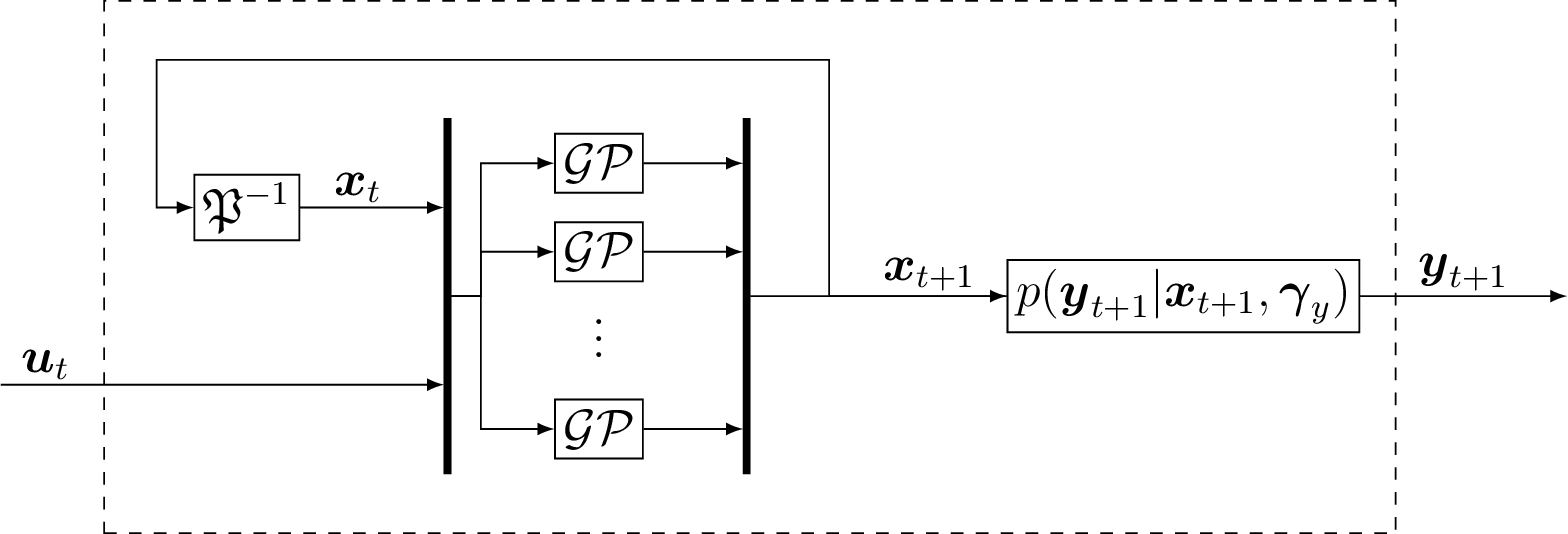
Gaussian process state space models are structured as a discrete-time system. In this case, the states are the regressors, which is visualized in Fig. 9. This approach allows to be more efficient, since the regressors are less restricted in their internal structure as in input-output models. Thus, a very efficient model in terms of number of regressors might be possible. The mapping from the states to the output is often be assumed to be known. The situation, where the output mapping describes a known sensor model, is such an example. It is mentioned in [Fri+13] that using too flexible models for both, the state mapping f and the output mapping, can result in problems of non-identifiability. Therefore, we focus on a known output mapping. The mathematical model of the GP-SSM is thus given by
where ξt ∈ ℝnξ, n ξ = nx + nu is the concatenation of the state vector xt ∈X ⊆ ℝnx and the input ut ∈ U ⊆ ℝnu such that ξ t = [xt; ut]. The mean function is given by continuous functions m1, …, mnx: ℝnξ → ℝ. The output mapping is parametrized by a known vector γ y ∈ ℝnγ with nγ ∈ ℕ. The system identification task for the GP-SSM mainly focuses on f in particular. It can be described as finding the state-transition probability conditioned on the observed training data.
Remark 6. The potentially unknown number of regressors can be determined using established nonlinear identification techniques as presented in [KL99], or exploiting embedded techniques such as automatic relevance determination [Koc16]. A mismatch leads to similar issues as in parametric system identification.
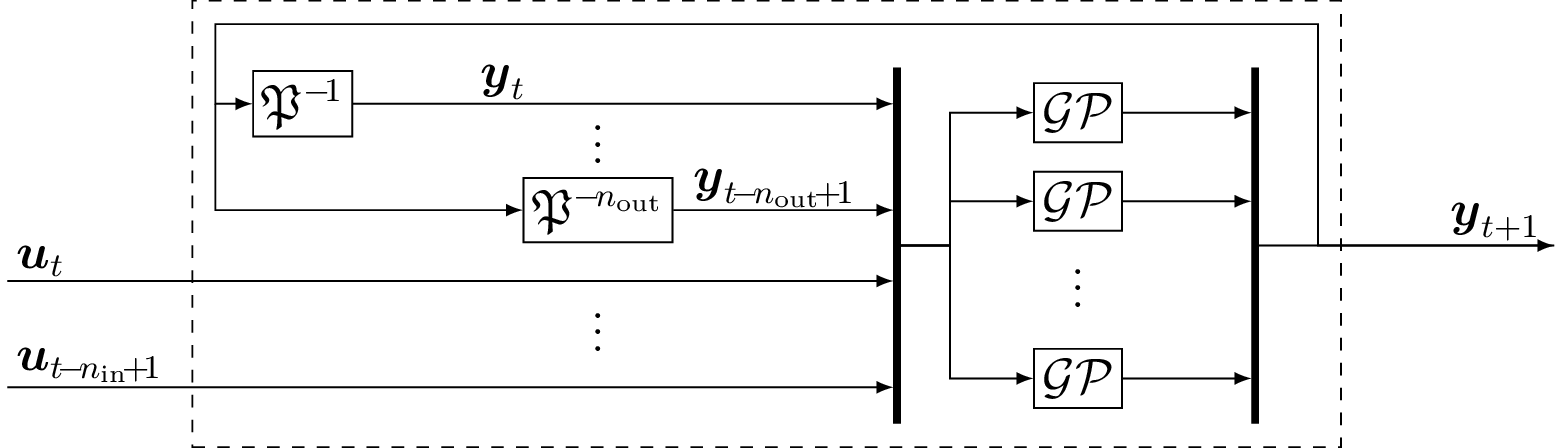
The GP-NOE model uses the past nin ∈ ℕ>0 input values ut ∈U and the past nin ∈ ℕ>0 output values yt ∈ ℝny of the model as the regressors. Figure 10 shows the structure of GP-NOE, where the outputs are feedbacked. Analogously to the GP-SSM, the mathematical model of the GP-NOE is given by
where ζt ∈ ℝnζ, n ζ = ninny + ninnu is the concatenation of the past outputs yt and inputs ut such that ζt = [yt−nin+1; …; yt; ut−nin+1; …; ut]. The mean function is given by continuous functions m1, …, mny: ℝnζ → ℝ. In contrast to nonlinear autoregressive exogenous models, that focus on one-step ahead prediction, a NOE model is more suitable for simulations as it considers the multi-step ahead prediction [Nel13]. However, the drawback is a more complex training procedure that requires a nonlinear optimization scheme due to their recurrent structure [Koc16].
Remark 7. It is always possible to convert an identified input-output model into a state-space model, see[PL70]. However, focusing on state-space models only would preclude the development of a large number of useful identification results.
Remark 8. Control relevant properties of GP-SSMs and GO-NOE models are discussed in [BH16b; BH16a; BH20].
In this article, we introduce the GP and its usage in GPR. Based on the property, that every finite subset of a GP follows a multi-variate Gaussian distribution, a closed-form equation can be derived to predict the mean and variance for a new test point. The GPR can intrinsically handle noisy output data if it is Gaussian distributed. As GPR is a data-driven method, only little prior knowledge is necessary for the regression. Further, the complexity of GP models scales with the number of training points. A degree of freedom in the modeling is the selection of the kernel function and its hyperparameters. We present an overview of common kernels and the necessary properties to be a valid kernel function. For the hyperparameter determination, two approaches based on numerical optimization are shown. The kernel of the GP is uniquely related to a RKHS, which determines the shape of the samples of the GP. Based on this, we compare different approaches for the quantification of the model error that quantifies the error between the GPR and the actual data-generating function. Finally, we introduce how GP models can be used as dynamical systems in GP-SSMs and GP-NOE models.
Let ν1 ∈ ℝnν1, ν 2 ∈ ℝnν2 with n ν1, nν1 ∈ ℕ be probability variables, which are multivariate Gaussian distribution
with mean μ1 ∈ ℝnν1, μ 2 ∈ ℝnν2 and variance Σ 11 ∈ ℝnν1×nν1, Σ 12 ∈ ℝnν2×nν1, Σ 22 ∈ ℝnν2×nν2. The task is to determine the conditional probability
The joined probability p(ν1, ν2) is a multivariate Gaussian distribution with
where x = [x1; x2], x1 ∈ ℝnν1, x 2 ∈ ℝnν2. The marginal distribution of ν 1 is defined by the mean μ1 and the variance Σ11 such that
The division of the joint distribution by the marginal distribution results again in a Gaussian distribution with
where the first part ∗ can be rewritten as
Thus, the covariance matrix Σ22|1 of the conditional distribution p(ν2|ν1) is given by
For the simplification of the second part ∗∗ of (63), we exploit the special block structure of Σ, such that its inverse is given by
with N = (Σ22 − Σ21Σ11−1Σ 12)−1. Thus, we compute ∗∗ as
Finally, the conditional probability is given with the conditional mean μ2|1 ∈ ℝnν2 and the conditional covariance matrix Σ22|1 ∈ ℝnν2×nν2 by
Mauricio A. Álvarez, Lorenzo Rosasco, and Neil D. Lawrence. “Kernels for Vector-Valued Functions: A Review”. In: Foundations and Trends in Machine Learning 4.3 (2012), pp. 195–266. doi: 10.1561/2200000036.
Nachman Aronszajn. “Theory of reproducing kernels”. In: Transactions of the American mathematical society 68.3 (1950), pp. 337–404. doi: 10.2307/1990404.
Felix Berkenkamp, Riccardo Moriconi, Angela P. Schoellig, and Andreas Krause. “Safe Learning of Regions of Attraction for Uncertain, Nonlinear Systems with Gaussian Processes”. In: 2016 IEEE 55th Conference on Decision and Control (CDC). 2016, pp. 4661–4666.
Felix Berkenkamp, Matteo Turchetta, Angela P. Schoellig, and Andreas Krause. “Safe Model-based Reinforcement Learning with Stability Guarantees”. In: Advances in Neural Information Processing Systems. 2017, pp. 908–918.
Thomas Beckers and Sandra Hirche. “Equilibrium distributions and stability analysis of Gaussian Process State Space Models”. In: 2016 IEEE 55th Conference on Decision and Control (CDC). 2016, pp. 6355–6361. doi: 10.1109/CDC.2016.7799247.
Thomas Beckers and Sandra Hirche. “Stability of Gaussian Process State Space Models”. In: 2016 European Control Conference (ECC). 2016, pp. 2275–2281. doi: 10.1109/ECC.2016.7810630.
Thomas Beckers and Sandra Hirche. “Prediction with Gaussian Process Dynamical Models”. In: Transaction on Automatic Control (2020). Submitted.
Christopher Bishop. Pattern recognition and machine learning. Springer-Verlag New York, 2006. isbn: 9780387310732.
Thomas Beckers, Dana Kulić, and Sandra Hirche. “Stable Gaussian Process based Tracking Control of Euler-Lagrange Systems”. In: Automatica 103 (2019), pp. 390–397. doi: 10.1016/j.automatica.2019.01.023.
Yusuf Bhujwalla, Vincent Laurain, and Marion Gilson. “The impact of smoothness on model class selection in nonlinear system identification: An application of derivatives in the RKHS”. In: 2016 American Control Conference (ACC). 2016, pp. 1808–1813. doi: 10.1109/ACC.2016.7525181.
Thomas Beckers, Jonas Umlauft, and Sandra Hirche. “Mean Square Prediction Error of Misspecified Gaussian Process Models”. In: 2018 IEEE Conference on Decision and Control (CDC). 2018, pp. 1162–1167. doi: 10.1109/CDC.2018.8619163.
Girish Chowdhary, Hassan Kingravi, Jonathan How, and Patricio A. Vela. “Bayesian nonparametric adaptive control of time-varying systems using Gaussian processes”. In: 2013 American Control Conference. 2013, pp. 2655–2661. doi: 10.1109/ACC.2013.6580235.
Lokenath Debnath, Piotr Mikusinski, et al. Introduction to Hilbert spaces with applications. Academic press, 2005.
Roger Frigola, Yutian Chen, and Carl E. Rasmussen. Variational Gaussian Process State-Space Models. 2014. arXiv: 1406.4905 [cs.LG].
Roger Frigola, Fredrik Lindsten, Thomas B. Schön, and Carl E. Rasmussen. “Bayesian inference and learning in Gaussian process state-space models with particle MCMC”. In: Advances in Neural Information Processing Systems. 2013, pp. 3156–3164.
Seymour Geisser and William F. Eddy. “A Predictive Approach to Model Selection”. In: Journal of the American Statistical Association 74.365 (1979), pp. 153–160. doi: 10.1080/01621459.1979.10481632.
Robert Keviczky and Haber Laszlo. Nonlinear system identification: input-output modeling approach. Springer Netherlands, 1999. isbn: 9780792358589.
Juš Kocijan. Modelling and Control of Dynamic Systems Using Gaussian Process Models. Springer International Publishing, 2016. doi: 10.1007/978-3-319-21021-6.
David J. MacKay. Gaussian Processes - A Replacement for Supervised Neural Networks? 1997.
Charles A. Micchelli, Yuesheng Xu, and Haizhang Zhang. “Universal kernels”. In: Journal of Machine Learning Research 7 (2006), pp. 2651–2667.
Oliver Nelles. Nonlinear system identification: from classical approaches to neural networks and fuzzy models. Springer-Verlag Berlin Heidelberg, 2013. doi: 10.1007/978-3-662-04323-3.
M. Q. Phan and R. W. Longman. “Relationship between state-space and input-output models via observer Markov parameters”. In: WIT Transactions on The Built Environment 22 (1970). doi: 10.2495/DCSS960121.
Neal M. Radford. Bayesian learning for neural networks. Springer-Verlag New York, 1996. doi: 10.1007/978-1-4612-0745-0.
Carl E. Rasmussen. Gaussian processes for machine learning. The MIT Press, 2006. isbn: 9780262182539.
John Shawe-Taylor and Nello Cristianini. Kernel methods for pattern analysis. Cambridge university press, 2004. doi: 10.1017/CBO9780511809682.
Ingo Steinwart and Andreas Christmann. Support vector machines. Springer Science & Business Media, 2008. doi: 10.1007/978-0-387-77242-4.
Ingo Steinwart, Don Hush, and Clint Scovel. “An explicit description of the reproducing kernel Hilbert spaces of Gaussian RBF kernels”. In: IEEE Transactions on Information Theory 52.10 (2006), pp. 4635–4643. doi: 10.1109/TIT.2006.881713.
Jonas Sjöberg, Qinghua Zhang, Lennart Ljung, Albert Benveniste, Bernard Delyon, Pierre-Yves Glorennec, Håkan Hjalmarsson, and Anatoli Juditsky. “Nonlinear black-box modeling in system identification: a unified overview”. In: Automatica 31.12 (1995), pp. 1691–1724. doi: 10.1016/0005-1098(95)00120-8.
Niranjan Srinivas, Andreas Krause, Sham M. Kakade, and Matthias W. Seeger. “Information-theoretic regret bounds for Gaussian process optimization in the bandit setting”. In: IEEE Transactions on Information Theory 58.5 (2012), pp. 3250–3265. doi: 10.1109/TIT.2011.2182033.
Jonas Umlauft, Thomas Beckers, and Sandra Hirche. “A Scenario-based Optimal Control Approach for Gaussian Process State Space Models”. In: 2018 European Control Conference (ECC). 2018, pp. 1386–1392. doi: 10.23919/ECC.2018.8550458.
Grace Wahba. Spline models for observational data. SIAM, 1990. doi: 10.1137/1.9781611970128.
Jack Wang, Aaron Hertzmann, and David M. Blei. “Gaussian process dynamical models”. In: Proceedings of the 18th International Conference on Neural Information Processing System. 2005, pp. 1441–1448. doi: 10.5555/2976248.2976429.
Christopher K. Williams and Carl E. Rasmussen. “Gaussian processes for regression”. In: Advances in neural information processing systems. 1996, pp. 514–520.